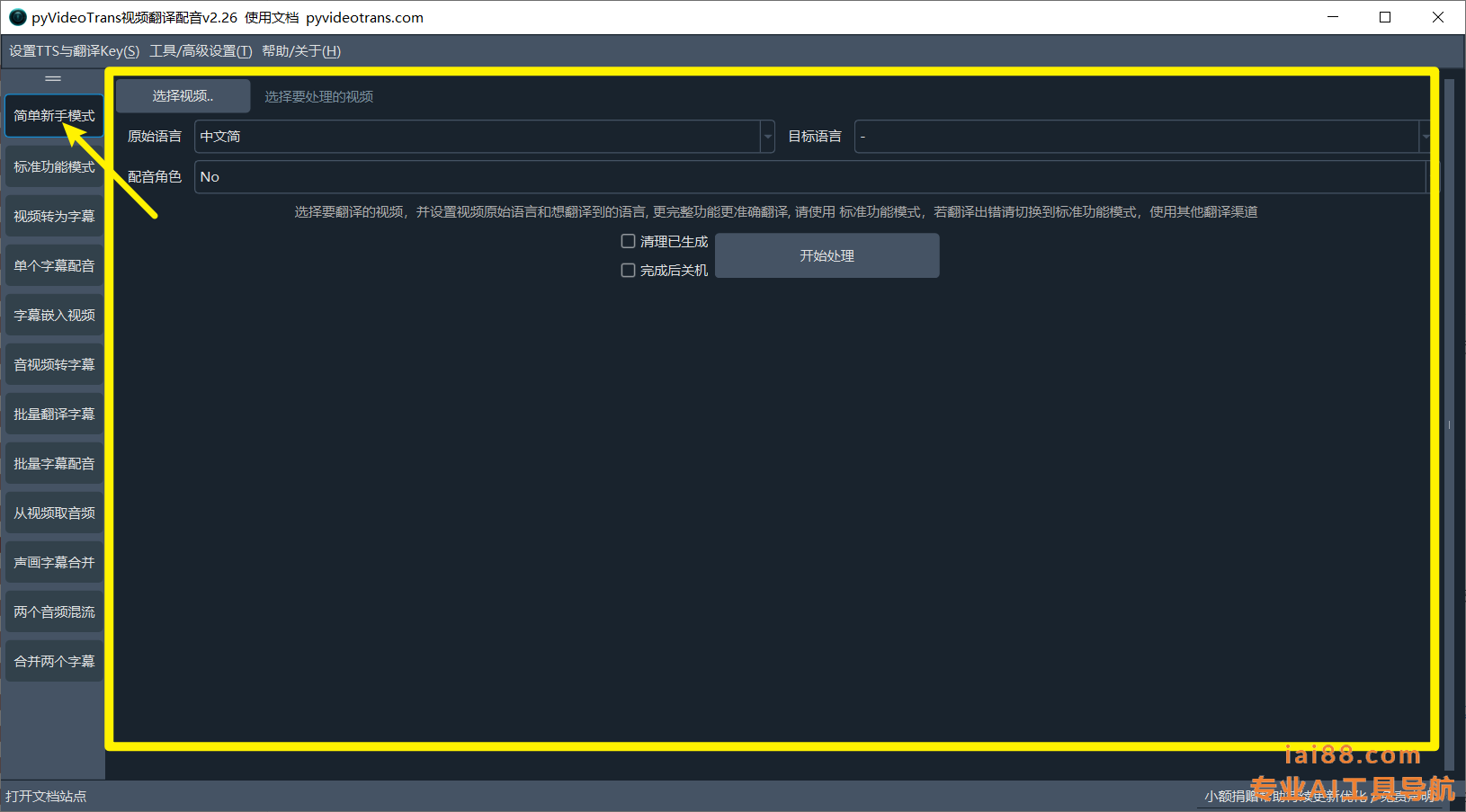
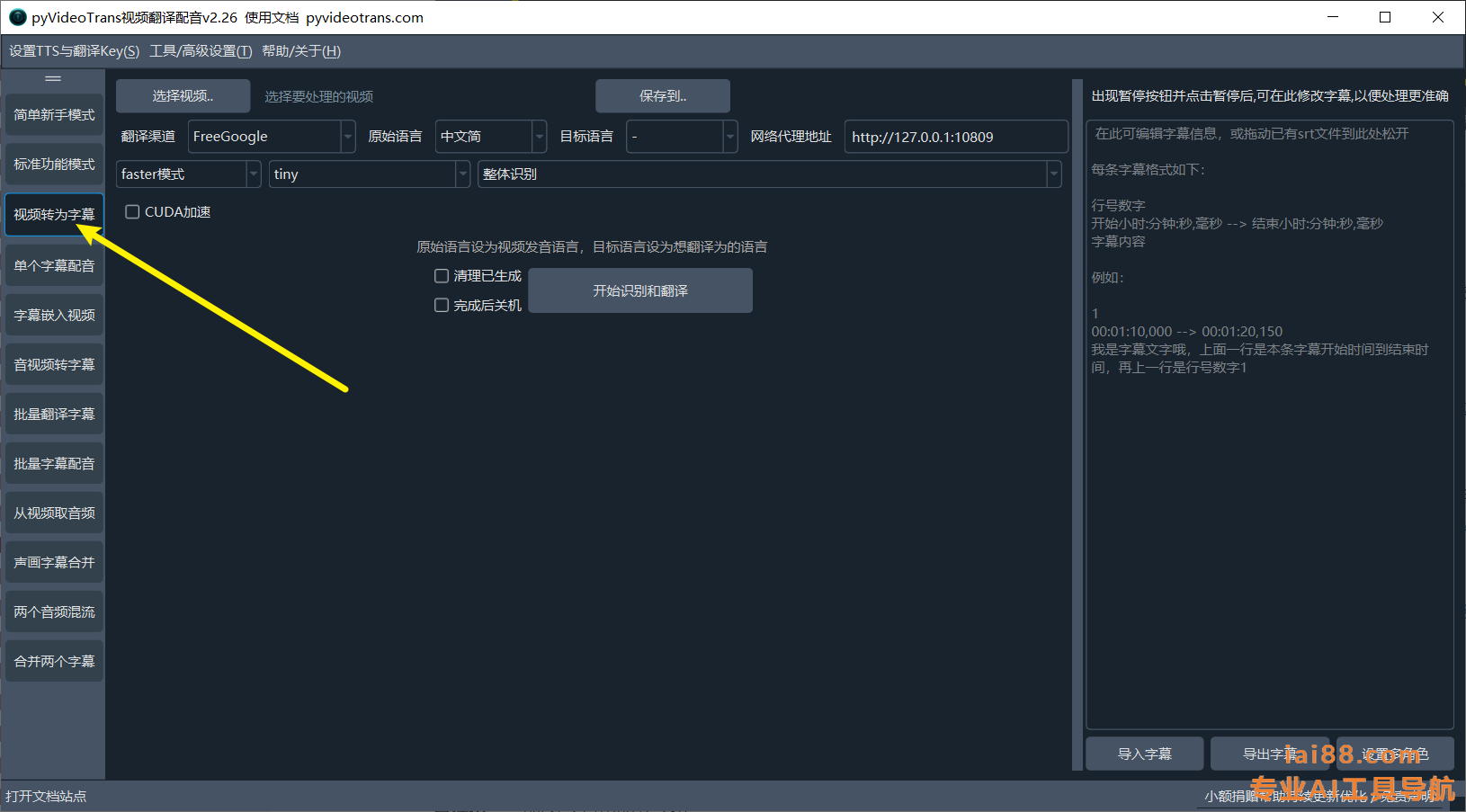
pyVideoTrans是一个视频翻译和配音工具,用于将视频从一种语言翻译到另一种语言,并添加配音。该工具能够将视频中的对话从一种语言自动翻译到另一种语言,并且可以添加配音,使得目标语言的观众能够更容易地理解和享受视频内容。这个工具可能包括了语音识别、机器翻译和语音合成等技术。

pyVideoTrans集成了 faster-whisper 模型和支持自定义 huggingface 模型的自动视频翻译工具,同时提供了批量语音转字幕、批量字幕翻译和批量配音的功能。
软件部署方式
pyVideoTrans支持多种部署方式,包括云端部署和本地部署,满足不同用户的需求:
- 云端部署:用户无需安装,只需通过Web端登录,即可使用所有功能,数据存储安全,更新维护方便。这个功能需要有技术经验和服务器资源的组织或个人才能完成。
- 本地部署:适用于对数据安全有高要求的用户,可在本地服务器部署,确保数据不外泄。本地部署,直接下载安装包,解压即可部署完成。
使用步骤简单
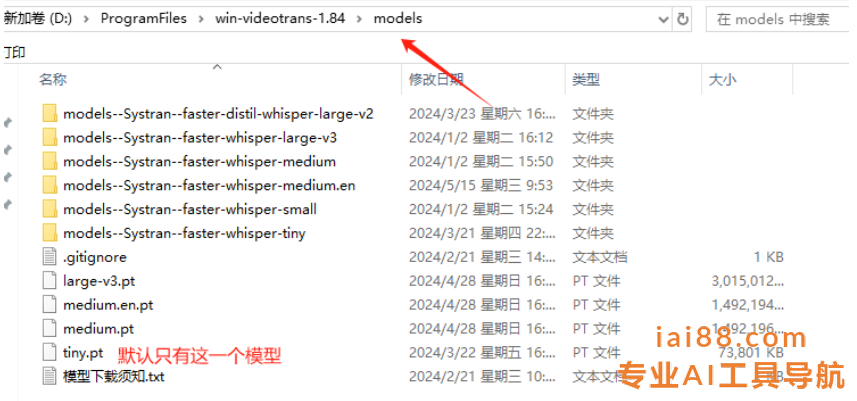
- 下载大模型(地址:https://pyvideotrans.com/model),放到本地文件夹【D:\Program Files\win-videotrans-2.23\models】下
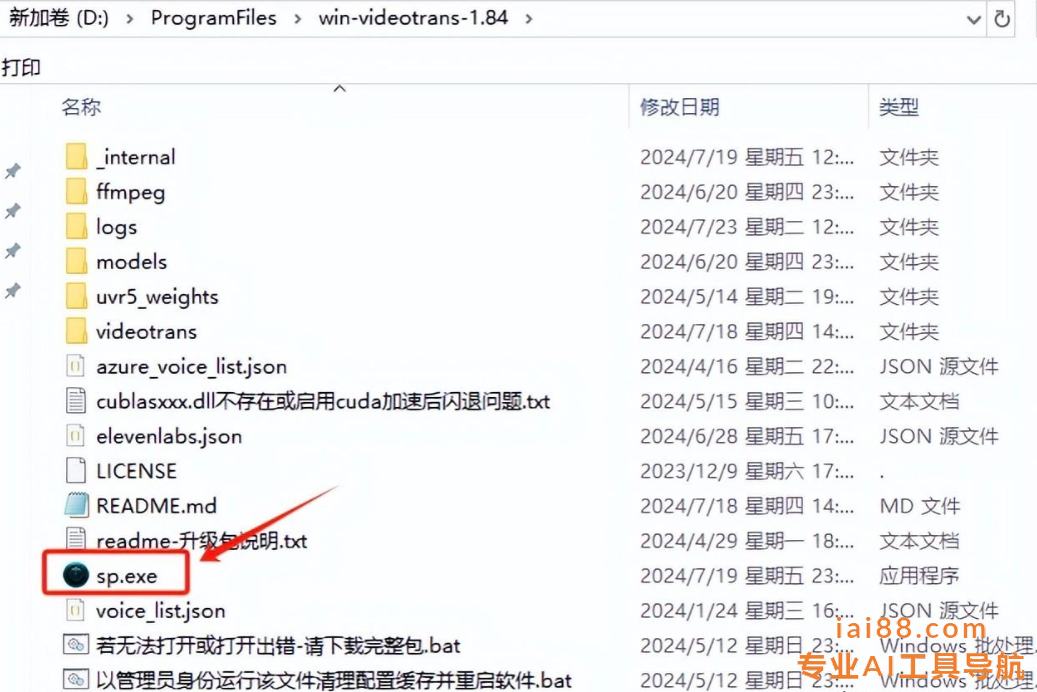
2 .打开软件:双击sp.exe,启动软件。
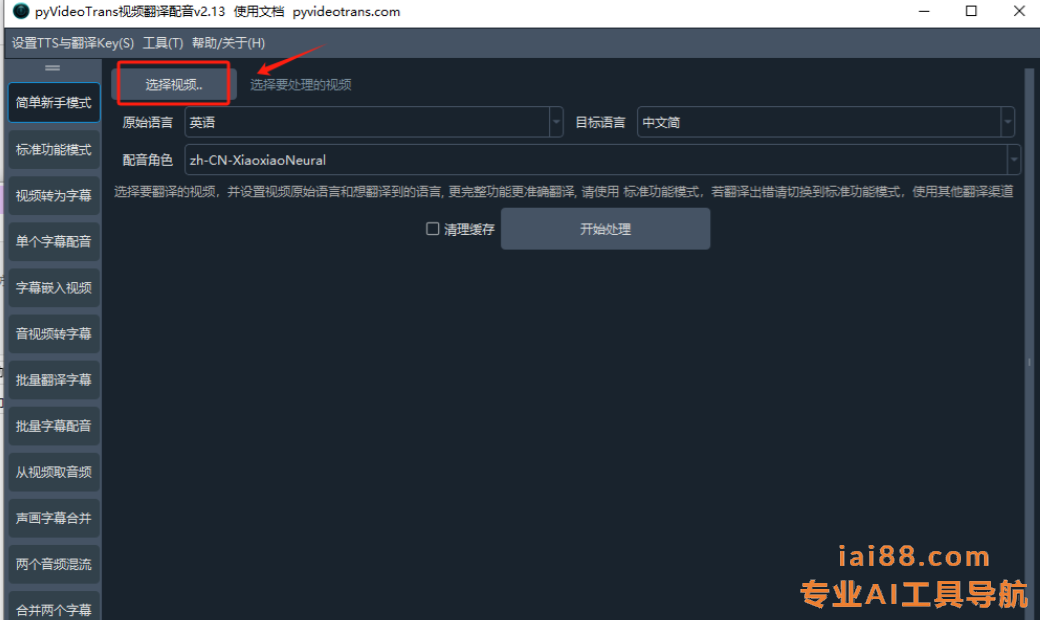
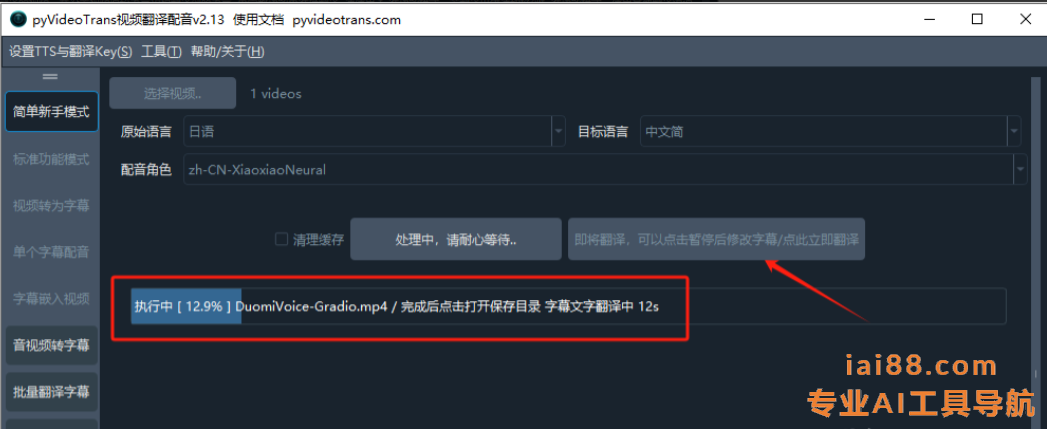
- 上传视频:选择需要翻译配音的视频文件,选择打开。
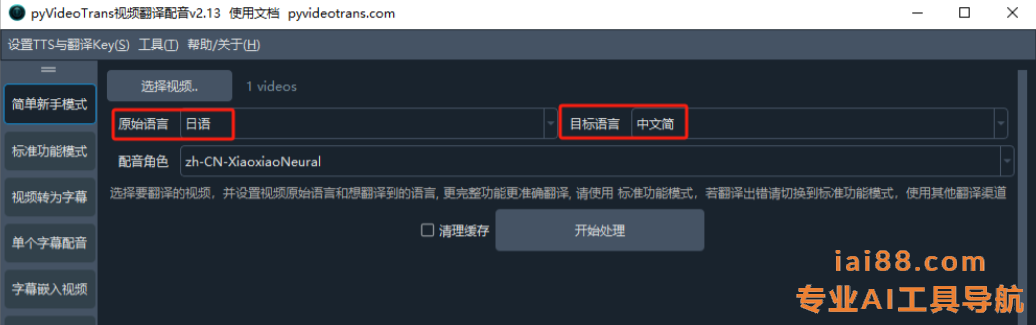
- 选择语言:根据需要,选择视频源语言和要译成的目标语言。
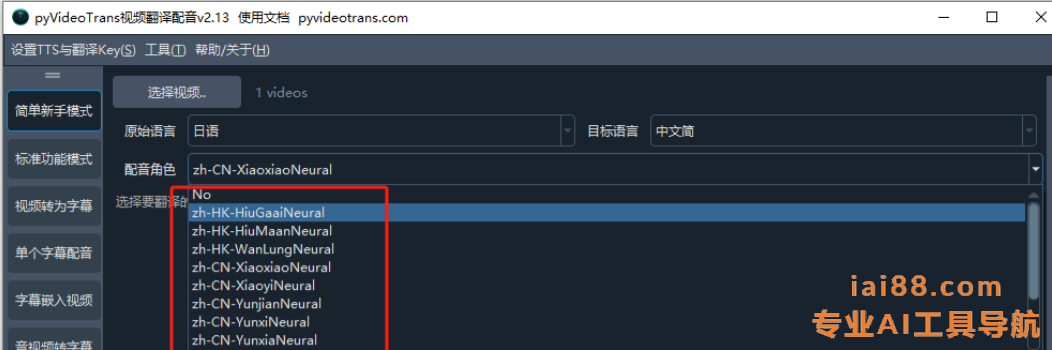
- 选择配音角色(就是用哪个声音配音):
有男有女,可自由选择。
在标准模式里,如果配置了ChatTTS应用,则可选角色会更多。
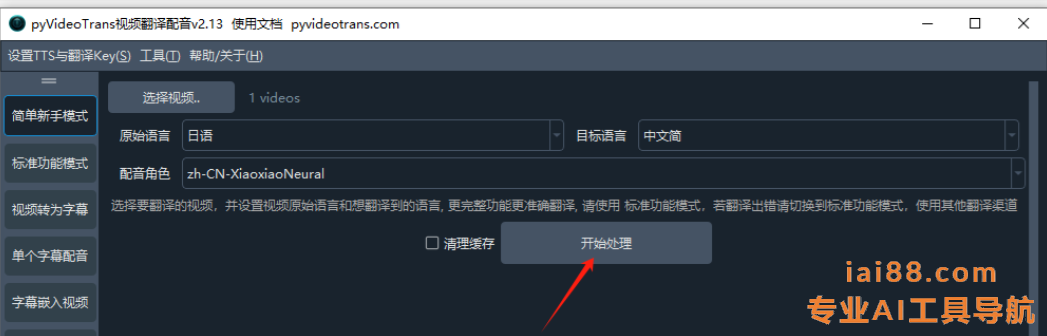
- 翻译配音:点击 开始处理,系统自动进行视频翻译和配音,用户可实时预览效果。
处理完毕,会在桌面右下角弹出【成功】的提示。
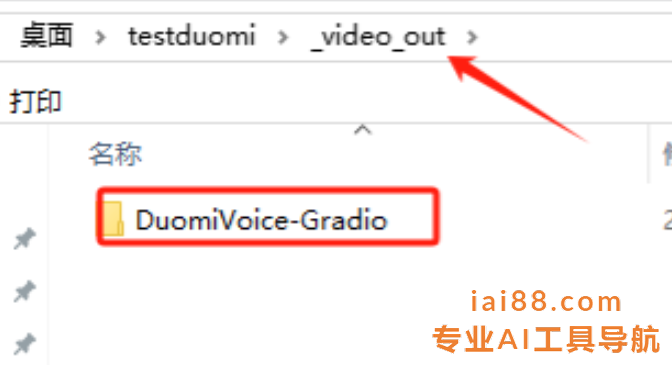
- 保存视频:翻译配音完成后,处理后的视频文件,保存至源文件夹下的_video_out文件夹。
模型注意事项
默认软件包的语音识别模型只包含tiny模型,就是最小尺寸模型,识别精度最低。
模型越大识别效果越好,所以需要从官网提供的网盘去单独下载,再存放到软件文件夹下的【model】文件夹下。
模型主要有2大技术类别,推荐使用faster-whisper 模型。
这点很重要,直接关系到最后的识别精度。
下载地址,存放路径前面已经说过,打开本详情页即可看到
用途
pyVideoTrans的应用场景广泛,适用于个人用户、教育机构、企业等多个领域:
- 个人用户:视频语音翻译成母语,观看外语电影、电视剧、学习课程,无需字幕,享受沉浸式观影体验。
- 教育机构:制作多语言教学视频,扩大国际影响力,提升教学质量。
- 企业:进行跨国会议、产品演示、培训视频的制作,进行有效沟通,提升企业形象。
实现技术原理
pyVideoTrans的核心技术包括:
语音识别(ASR)、机器翻译(MT)和语音合成(TTS)3大部分。
- 语音识别(ASR):通过深度学习模型,将视频中的语音抽离,并转换为文本,准确率高,支持多场景识别。
- 机器翻译(MT):采用神经网络翻译模型,实现高质量的多语言翻译,保持原意和风格。
- 语音合成(TTS):结合情感分析和语调模型,合成自然流畅、情感丰富的人声配音。
开源地址:https: