













腾讯混元发布并开源的语音数字人模型HunyuanVideo-Avatar,由腾讯混元视频大模型(HunyuanVideo)及腾讯音乐天琴实验室MuseV技术联合研发,支持头肩、半身与全身景别,以及多风格、多物种与双人场景,面向视频创作者提供高一致性、高动态性的视频生成能力。用户可上传人物图像与音频,HunyuanVideo-Avatar模型会自动理解图片与音频,比如人物所在环境、音频所蕴含的情感等,让图中人物自然地说话或唱歌,生成包含自然表情、唇形同步及全身动作的视频。
目前支持上传不超过14秒的音频进行视频生成,后续将逐步上线和开源其他能力。
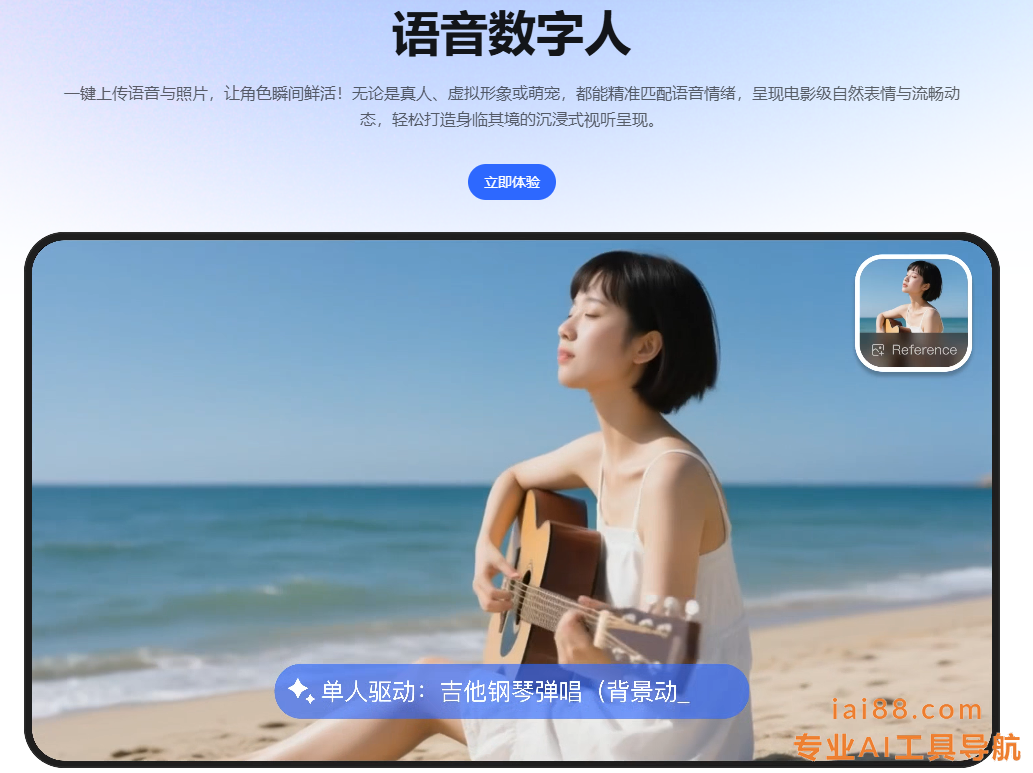
当用户输入一张拿着吉他的坐在沙滩的女性图片和一段抒情音乐。
模型会自行理解“她在海边弹吉他,唱着非常抒情的歌曲”,并生成一段图中人物在弹唱的视频。
可以生成人物在不同场景下的说话、对话、表演等片段,快速制作产品介绍视频或多人互动广告,降低制作成本。
相关导航






暂无评论...