剑桥大学计算机科学博士创立的AI研究实验室Memories AI正式发布,推出了全球首个人工智能大型视觉记忆模型(Large Visual Memory Model,简称LVMM)。这一突破性技术旨在赋予AI类人般的视觉记忆能力,让机器能够像人类一样“看到、理解并记住”视觉信息。
全球首创:大型视觉记忆模型(LVMM)
Memories AI的核心技术是其独创的大型视觉记忆模型(LVMM),这是业内首个能够持续捕获、存储和回忆视觉信息的AI架构。与现有AI系统不同,传统模型通常只能处理短时视频片段(15-60分钟),在长时间视频分析中会丢失上下文,导致无法回答“之前是否见过这个?”或“昨天发生了什么变化?”等问题。而LVMM通过模拟人类记忆机制,能够处理长达数百万小时的视频数据,构建持久、可搜索的视觉记忆库。
这一技术通过三层架构实现:首先对视频进行降噪和压缩,提取关键信息;其次创建可搜索的索引层,支持自然语言查询;最后通过聚合层将视觉数据结构化,使AI能够识别模式、保留上下文并进行跨时间比较。这使得Memories AI在处理大规模视频数据时,展现出前所未有的效率和准确性,号称比现有技术高出100倍的视频记忆容量。
Memories AI的LVMM技术涵盖场景:
– 物理安全:为安防公司提供异常检测功能,通过分析长时间监控视频,快速发现潜在威胁。
– 媒体与营销:帮助营销团队分析社交媒体上的海量视频内容,识别品牌提及、消费者趋势和情感倾向。例如,某社交媒体平台已利用Memories AI技术洞察TikTok等平台的长期趋势,保持竞争优势。
– 机器人与自动驾驶:通过赋予AI长期视觉记忆,支持机器人执行复杂任务,或帮助自动驾驶汽车记住不同路线的视觉信息。
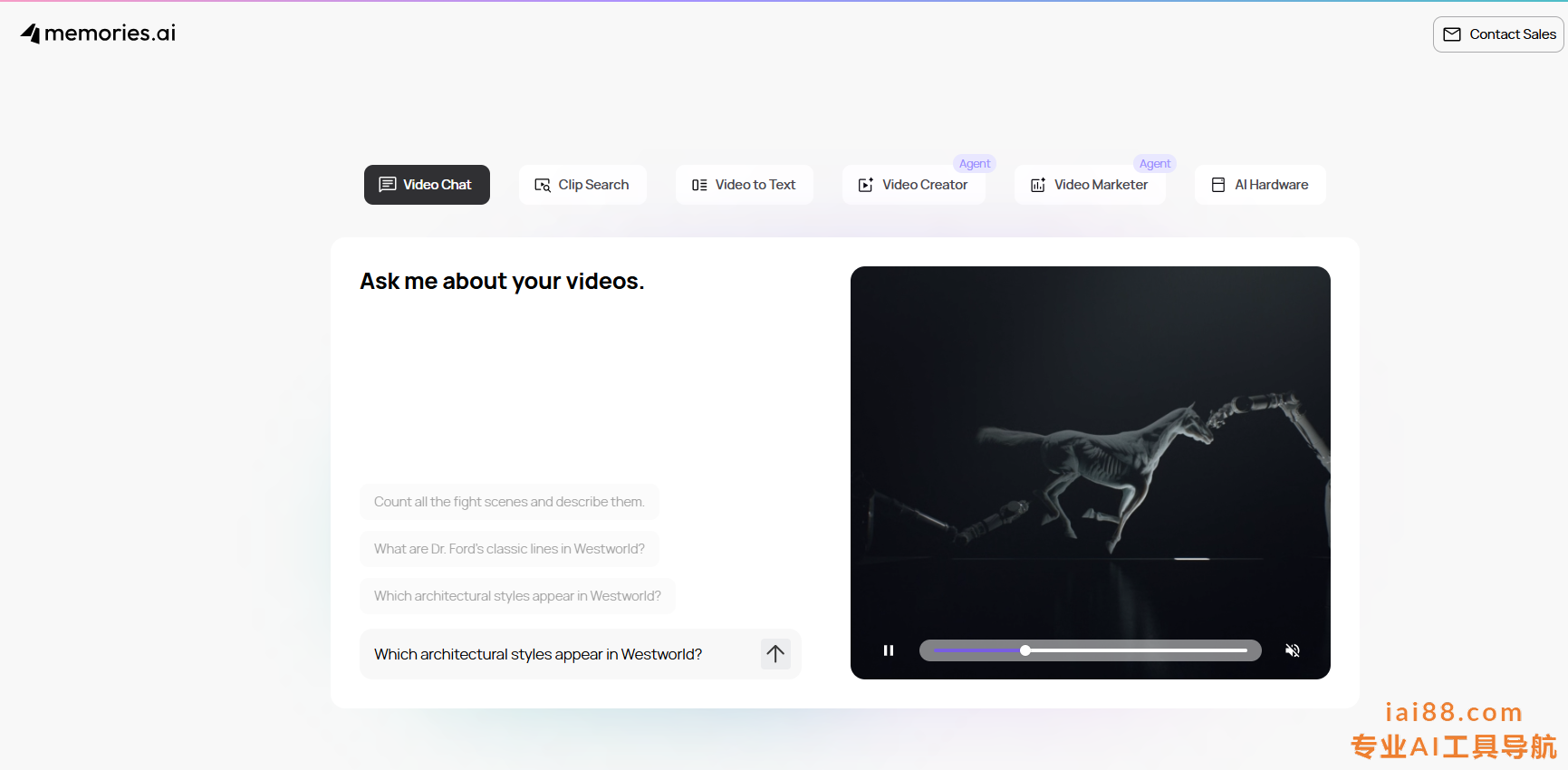
Memories AI的平台支持通过API或聊天机器人网页应用访问,用户可以上传视频或连接自己的视频库,通过自然语言查询视频内容。这种灵活的交互方式使其适用于从企业级解决方案到个人化应用的广泛场景。