美团于正式发布 LongCat-Flash-Chat,并同步开源。据官方介绍,LongCat-Flash采用创新性混合专家模型(Mixture-of-Experts, MoE)架构,总参数560B,激活参数18.6B-31.3B(平均 27B)。据多项基准测试综合评估,LongCat-Flash-Chat在仅激活少量参数的前提下,在智能体任务中具备突出优势,同时推理速度超过100tps。
-
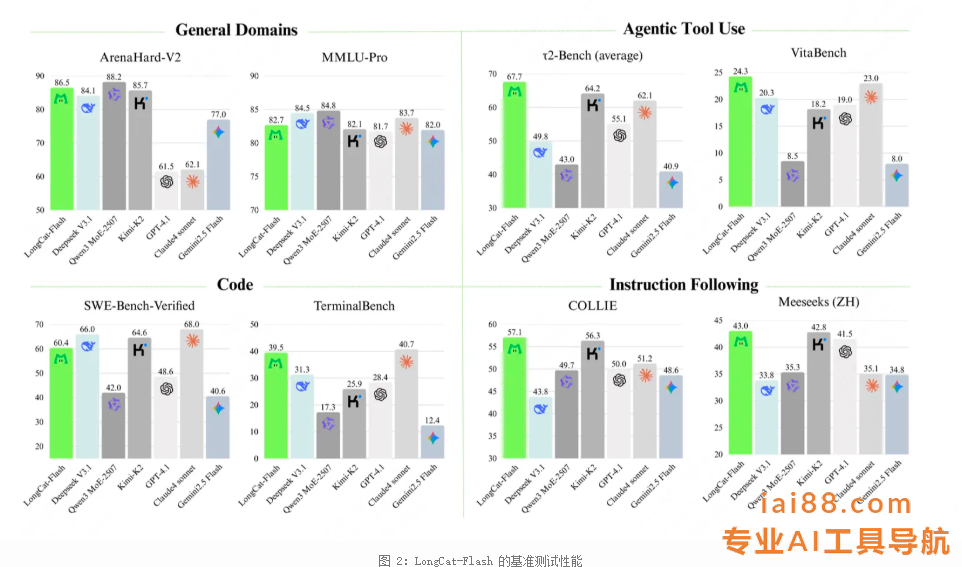
在 通用领域知识 方面,LongCat-Flash 表现出强劲且全面的性能:在 ArenaHard-V2 基准测试中取得 86.50 的优异成绩,位列所有评估模型中的第二名,充分体现了其在高难度“一对一”对比中的稳健实力。在基础基准测试中仍保持高竞争力,MMLU(多任务语言理解基准)得分为 89.71,CEval(中文通用能力评估基准)得分为 90.44。这些成绩可与目前国内领先的模型比肩,且其参数规模少于 DeepSeek-V3.1、Kimi-K2 等产品,体现出较高的效率。
-
在 智能体(Agentic)工具使用 方面,LongCat-Flash 展现出明显优势:即便与参数规模更大的模型相比,其在 τ2-Bench(智能体工具使用基准)中的表现仍超越其他模型;在高复杂度场景下,该模型在 VitaBench(复杂场景智能体基准)中以 24.30 的得分位列第一,彰显出在复杂场景中的强大处理能力。
-
在 编程 方面,LongCat-Flash 展现出扎实的实力:其在 TerminalBench(终端命令行任务基准)中,以 39.51 的得分位列第二,体现出在实际智能体命令行任务中的出色熟练度;在 SWE-Bench-Verified(软件工程师能力验证基准)中得分为 60.4,具备较强竞争力。
-
在 指令遵循 方面,LongCat-Flash 优势显著:在 IFEval(指令遵循评估基准)中以 89.65 的得分位列第一,展现出在遵循复杂且细致指令时的卓越可靠性;此外,在 COLLIE(中文指令遵循基准)和 Meeseeks-zh(中文多场景指令基准)中也斩获最佳成绩,分别为 57.10 和 43.03,凸显其在中英文两类不同语言、不同高难度指令集上的出色驾驭能力。