













百灵大模型再度出手,正式发布并开源通用语言大模型 Ling-1T ——蚂蚁迄今为止开源的参数规模最大的语言模型。
Ling-1T 自百灵大模型 「Ling 2.0 系列」,延续了蚂蚁自研的高效 MoE( Mixture of Experts )架构,它也是该系列的首款旗舰产品。而1T( Trillion,万亿)级的总参数规模,让人再次直观感受到开源模型的「体量战争」还在加速升级。
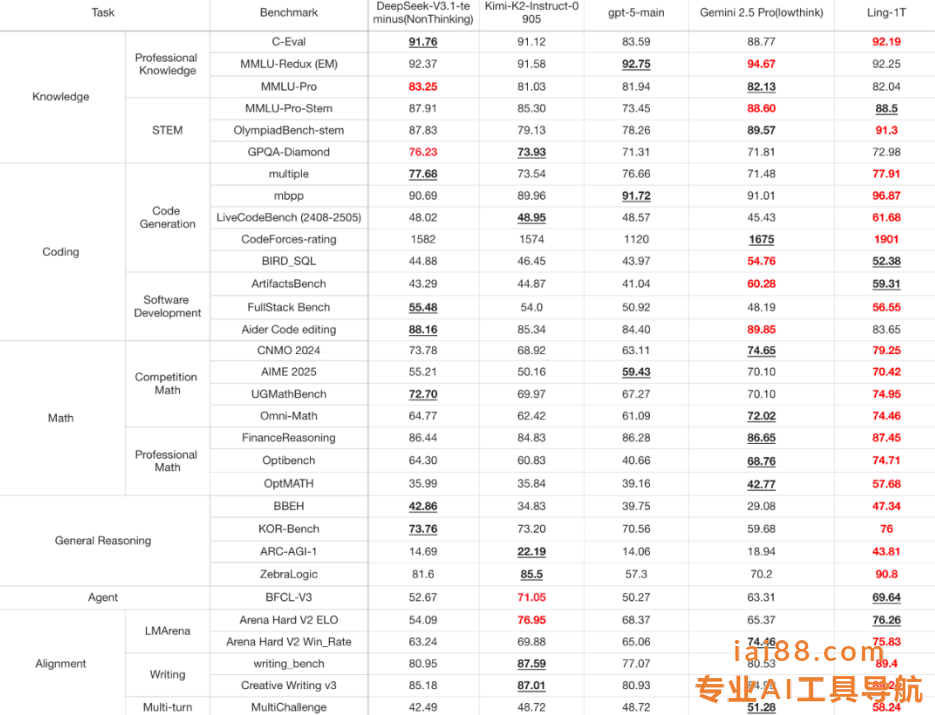
Ling-1T(最右列)与几款具有代表性的旗舰模型的比较,包括大参数量的开源模型(DeepSeek-V3.1-Terminus、Kimi-K2-Instruct-0905)与闭源 API(GPT-5-main、Gemini-2.5-Pro)。
最引人注目的是编程与数学推理( Coding & Math )两大核心维度的表现。这些被称为高推理密度的任务,是大模型能力的天花板所在,而 Ling-1T 仍稳居第一梯队。
例如,在 LiveCodeBench(真实编程推理任务) 上,Ling-1T 得分最高,显著高于 DeepSeek;在 ArtifactsBench(复杂软件逻辑建模) 中,得分59.31,仅次于Gemini-2.5-Pro。
数学方面,在综合测试中,Omni-Math 与 UGMathBench 双双突破 74 分大关,稳居领先位置;在 FinanceReasoning(金融推理)中表现更稳,达到 87.45,展现出强大的逻辑一致性与跨领域推理能力。
知识理解( Knowledge )维度同样出色。Ling-1T在多个关键数据集上均处于领先或并列领先位置:
C-Eval(92.19)、MMLU-Redux(92.25)、MMLU-Pro(82.04)、MMLU-Pro-STEM(88.5)、OlympiadBench(91.3)。
这些分数整体比 DeepSeek、Kimi、GPT-5 主干模型普遍高出1~3 个百分点,部分指标甚至逼近Gemini-2.5-Pro 的上限。
这表明它不仅知识密度高、泛化能力强,更具备深度思考与逻辑推理的内在一致性。
在 Agent 推理与多轮对话( Multi-turn Reasoning )场景中,Ling-1T 的表现同样亮眼。尤其在 BFCL-v3 与 Creative-Writing 等具备开放思维特征的任务中,展现出自然语言表达与思维连贯性的平衡能力——不仅「会答题」,还「懂思考」。





