













阿里巴巴旗下的通义实验室近期在音频技术领域迈出了重要一步,正式推出了其首个开源音频生成模型——ThinkSound。这一创新模型的最大亮点在于,它将思维链(CoT)技术首次融入音频生成过程,意在克服现有视频转音频(V2A)技术在理解和表达视频动态细节及事件逻辑方面的局限。
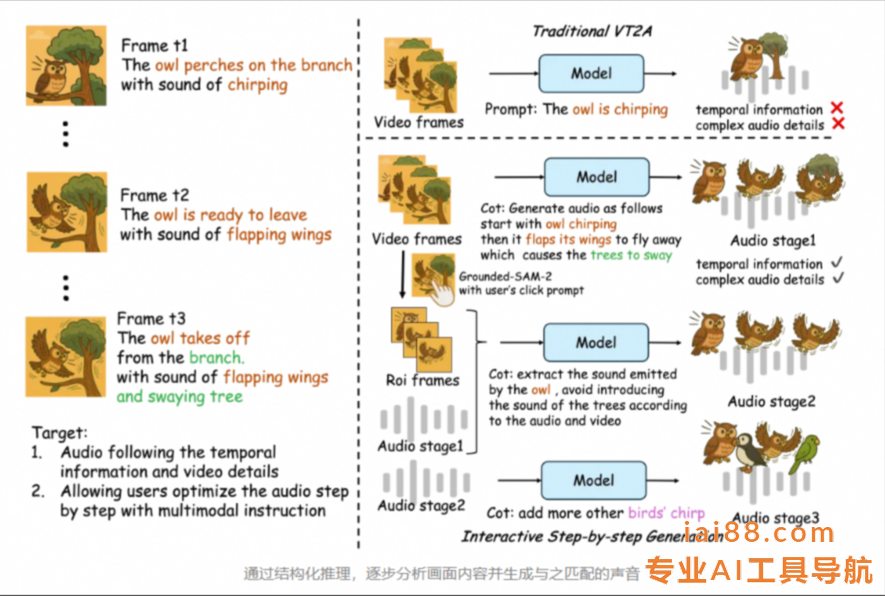
据通义语音团队详细介绍,传统的V2A技术往往难以精确捕捉视频画面与声音之间的时空对应关系,导致生成的音频与视频中的关键事件无法准确同步。而ThinkSound通过引入一种结构化的推理机制,模拟了人类音效师的工作流程:首先,它理解视频的整体内容和场景语义;接着,聚焦于具体的声源对象;最后,根据用户的编辑指令,逐步生成高度逼真且与视频内容同步的音频。
该模型已经面向开发者开源,他们可以在GitHub、Hugging Face和魔搭社区等平台上获取相关的代码和模型。这一开源举措无疑将促进音频生成技术的进一步发展和创新,同时也为游戏、虚拟现实(VR)、增强现实(AR)等沉浸式应用场景提供了更多可能性。
相关导航





暂无评论...